
The NuGet.org Architecture
As part of Building NuGet 3.x, we have been working on a significant re-architecture of NuGet.org. Progress has been steady and we are starting to see a return on investment. In this post, we’ll compare the legacy architecture to where we’ll be in the near future.
Legacy Architecture
One of the goals when the NuGet Gallery project was started in 2011 was to provide a reference ASP.NET MVC application hosted in Azure. The project would follow our own prescriptive guidance and leverage the frameworks we build within our group:
- ASP.NET MVC and Razor
- SQL Azure
- EntityFramework Code-First
- WCF Data Services and OData
- Azure Web Roles
- Azure Storage
Legacy Architecture Diagram
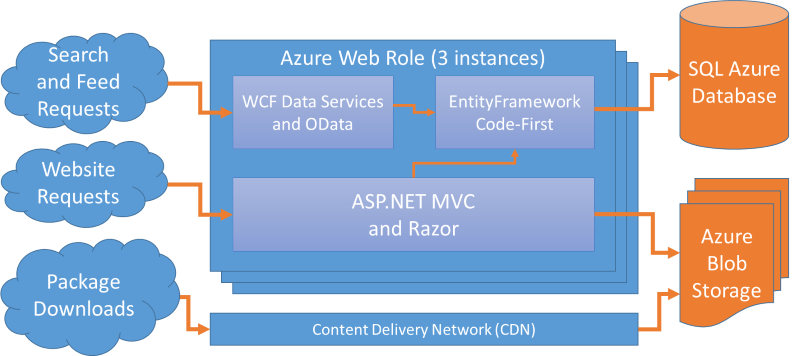
Deployment Details
Deploying this architecture was really straight-forward.
- An Azure Web Role (3 instances, allowing redundancy even when one instance is being updated)
- A SQL Azure database
- An Azure Storage account
- One container with public blobs for serving packages
- One container with private blobs for in-progress package uploads
We also used EntityFramework’s database migrations, running them automatically when we deployed a new Web Role, and thereby keeping our production database schema in sync with the running code.
During a deployment, we’d publish the update to the Web Role’s Staging slot, perform verification, and then do a VIP swap.
Performance Over Time
When the gallery was first introduced, the initial impression was that the site was fast.
Congrats to @JeffHandley and @haacked and team on the new #nuget site launch! http://nuget.org #fast
— Scott Hanselman (@shanselman)
December 6, 2011 was a good day. We were proud of the new gallery. The code was simple, worthy of showcasing as “how to build web applications to run in Azure.” And the users agreed; the reception was thoroughly positive.
Fast forward a couple of years though, and complaints about NuGet being slow became commonplace. Search was slow, package installations were slow, the website was slow, everything was slow. Even worse, people regularly complained about NuGet being down. Any interruption in SQL Azure or Azure Web Roles would directly affect the gallery.
Scalability Characteristics
With the legacy architecture, let’s take a look at what happens when a you right-click on a project and select ‘Manage NuGet Packages’.
- From the Online tab, the NuGet dialog issues an OData query to perform a package search
- On the server, the OData query flows through WCF Data Services, to EntityFramework, and then to SQL Azure
- The results of the query are projected into an entity type that is returned in OData’s XML ATOM format
- The client processes the response using WCF Data Services’ client library and renders the results
This means that every time a user opens the NuGet dialog in Visual Studio, we perform a SQL query. In 2011 that was okay, but after NuGet started shipping with Visual Studio, it quickly became a scalability nightmare. We were essentially hitting ourselves with a distributed denial of service attack. This became all too clear the day that Visual Studio 2012 shipped with NuGet in the box, and the feed went down for several hours.
NuGet Package Restore exacerbated the scalability challenges. This feature allows projects to omit packages from source control and download them during build. Since the packages are served from Azure Storage, it shouldn’t be that big of a deal; except the NuGet client needs to discover the package URL from the OData feed. As you might guess, this results in a SQL query. And any time we failed to process that query in time, builds would break. Ouch!
We Had it Backwards
NuGet.org is an extremely read-heavy system, with millions of reads for every write, yet the architecture favored write-heavy systems that need to be immediately consistent. SQL Server, EntityFramework, and WCF Data Services with OData are great for systems where you have a relatively small number of users performing a similar number of reads and writes and where changes must be immediately reflected. But we have millions of users who need to reliably perform reads on relatively static data. Our architecture should reflect that.
It’s difficult and costly to scale a fully consistent system to support the number of users that NuGet has. Fortunately, most of NuGet doesn’t need to be fully consistent; eventual consistency (within a few minutes or less) will suffice. Embracing this mindset with patterns like Command Query Responsibility Segregation (CQRS) and Event Sourcing enables us to work toward avoiding compute for the vast majority of NuGet’s reads. This approach will address the scalability concerns we have with the current system.
Tomorrow’s Architecture
The majority of the NuGet team is now working on a new architecture. When we began the effort, we knew we needed to:
- Define availability goals while identifying which scenarios require immediate consistency or compute
- Separate reads from writes for scenarios that don’t require immediate consistency
- Optimize for incremental updates through since we have a relatively low number of writes
Availability Goals
When we look at the NuGet.org service, we can break it down into a few buckets with different availability goals:
- Registration, Login, and Package Uploads – these require writes and/or immediate consistency
- Registering a user and uploading a package write to the system
- If a user changes their password or API key, that needs to be immediately enforced for logins and uploads
- Package publishing must confidently identify package id/version conflicts
- Goal: Good Availability at 99.9% – interruptions don’t affect package consumers
- Search – this requires server compute but can be eventually consistent
- If it takes a few moments for a newly published package to make it into the search index, that’s acceptable
- We can keep the entire index in memory for extremely fast responses
- Goal: High Availability at 99.99% – interruptions block package discovery
- Package Installation and Restore – this should not require server compute and can be eventually consistent
- It can take a few moments for a newly published package to become available on the feed
- And once a package is published, it’s very rarely updated and then only its metadata can be modified
- Goal: Maximum Availability at 99.999% – interruptions break builds
Separate Reads from Writes
With these goals and scenarios clearly defined, we then understood what we needed to do:
- Keep the existing CRUD-style architecture for registration, login, and package uploads
- We might revisit this later but we’re within reach of the availability goal already
- We believe by disconnecting other reads from this subsystem we’ll hit the goal easily
- Build an independently scalable Search Service
- Use compute (Lucene.NET) but don’t require external resources for requests
- Persist the index in Storage, update it incrementally, and cache the entire index in memory
- Use the query model to produce materialized presentations
- While OData allows us to expose our data model for the client to query however it wants, it’s impossible to make all of the client queries efficient
- Task-based presentations can be produced for serving the client’s specific needs very efficiently
- We must be able to quickly detect changes in the write store and update all affected presentations of the data
- This can all be done asynchronously with fault tolerance and parallelism
- Materialized presentions can be persisted into Azure Storage and served from the CDN
Optimize for Incremental Updates
With the conclusion that we didn’t want to change the CRUD-style architecture for the website and package uploads, we needed an approach for layering incremental update processing on top of the existing system. The database behind the website and package uploads will remain as-is, but we will query it from the back-end worker to extract changes. Then we’ll use the set of incremental changes to apply the updates to the Search Service and task-based presentations.
We started with the Search Service. With its index in storage and cached in memory, we built a job in our Work Service to compare the database’s package data to what is stored in the Lucene index. We fine-tuned this and reached a point where we can update the index every minute without incurring any costly load on the database. This has been running in production for a few months and we’ve proven that we can effectively and efficiently extract and process incremental updates from our existing database.
With that success behind us, we moved onto building a pipeline to produce presentation models to be used by the client. We can produce a full catalog of NuGet.org’s packages, efficiently and incrementally update it, transform those updates into the task-based presentation models, and persist those models into Azure Storage. We’re making changes to the NuGet client to read these presentations out of storage through our CDN instead of making OData queries.
Patching the Legacy Architecture
Knowing that the full server and client changes would take several months to get into place, we’ve been incrementally patching the legacy architecture. Here’s what is in place today:
- (Unchanged) ASP.NET MVC and Razor
- (Unchanged) SQL Azure
- (Unchanged) EntityFramework Code-First
- (Modified) WCF Data Services and OData, but with high-traffic queries getting intercepted
- (Unchanged) Azure Web Roles
- (Unchanged) Azure Storage
- (New) Lucene.NET-based Search Service, intercepting the Search and Package Restore queries
- (New) A separate SQL database for package statistics
- (New) A Work Service that processes async back-end jobs like migrating statistics data and producing reports
- (New) An additional SQL database for managing the queue of back-end work
A subtle but impactful difference is that we intercept OData requests for Search and Package Restore and produce those results through our Search Service instead of allowing those queries to reach the SQL database. We update the search index asynchronously using back-end jobs. We also introduced a second SQL database with a star schema for producing package statistics reports and then a third SQL database for managing the Work Service’s queue.
Current Patched Architecture Diagram
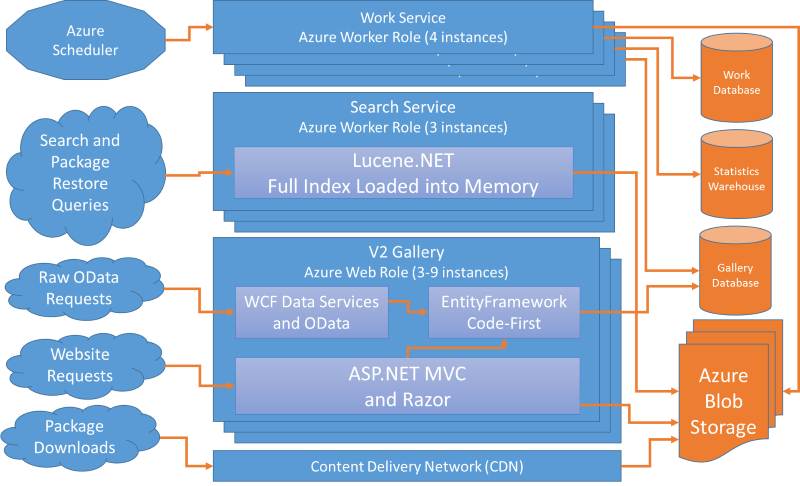
These changes introduced both the new Search Service and the Work Service as Azure Worker Roles. But we’ve also made some other deployment changes to improve availability of the gallery.
- We deploy the front-end Web Role to two data centers
- Azure Traffic Manager sits in front, in fail-over mode
- The secondary data center runs in a read-only configuration against a recent SQL backup
- If our primary data center fails, we are then failed-over to a recent read-only clone
- We deploy the Search Service Worker Role to two data centers
- Azure Traffic Manager sits in front, in fail-over mode
- Both front-end deployments access the Search Service through its Traffic Manager endpoint
- The front-end Web Role has Azure’s Auto-Scale feature enabled
- We generally run on 3 Medium instances
- We can scale up to 9 instances under heavy load
- It’s configured to keep CPU utilization between 60%-80%
- It scales up 1 instance at a time, waiting at least 10 minutes between scale actions
- It scales down 1 instance at a time, waiting 20 minutes between scale actions
- This allows us to scale up pretty quickly, but scale down a bit slower
- The Work Service is deployed as a Worker Role in Azure
- We currently run 4 instances and it performs a lot of back-end work
- We use Azure Scheduler to add jobs into the Work Service queue
- This is done through HTTP PUTs into the Work Service’s HTTP endpoint
Deploying API v3
Our current OData-based API is NuGet’s second API format, therefore we’ve been referring to our new implementation and the materialized presentation models as “API v3”. We are preparing to deploy API v3 in a CTP form very soon and we’ll post more details about it at that time. We know that we’ll be making quite a few changes between CTP and the stable release but we’ll invite ecosystem partners to work against the API and give us feedback.
What We’re Achieving
This new architecture helps us achieve some fundamental capabilities:
- Fast and Reliable Search Service
- We incrementally update our search index and persist it into Azure Storage
- The Search service loads the index entirely into memory
- Search queries from both the client and the website are routed to the Search service’s HTTP endpoint where results are generated without loading any external resources
- The Search service is independently scalable with Traffic Manager routing to a secondary data center when needed
- Efficient Dependency Resolution
- The client’s requests are completely predictable – there’s no reason to compute the responses per request
- We materialize dependency resolution presentations and serve them directly from storage through our CDN
- These presentations contain all of the detailed dependency information for all versions of a package so the client can make very few HTTP requests to collect what it needs to construct the dependency graph
- If the client needs different data for dependency resolution over time, we modify these presentations easily without ramifications to other parts of the system
- Highly Available Package Installation and Restore
- Once a package id/version pair is known for installing or restoring a package, it must be fast and reliable
- A lookup needs to occur to check the existence of a package id/version and discover its download URL
- We also want to capture metrics for package statistics, knowing when/why packages are downloaded, but that can be done separately from the actual act of downloading the package
- Improved Ability to Implement New Features
- We have a long list of features we want implement that would require the client getting more data from the server
- The new architecture gives us the ability to expose data in a scalable and reliable way
- We can also produce new feature-specific presentations when needed for new features without modifying existing presentations that are used in other scenarios
 Light
Light Dark
Dark
0 comments